Summary & Quick Verdict:
Data harvesting itself is entirely legal. Global courts, including the landmark U.S. hiQ Labs v. LinkedIn ruling, have established that extracting publicly accessible, non-copyrighted data does not violate federal anti-hacking laws. However, is web scraping legal if you bypass logins, harvest personal data, or crash a server? Absolutely not. While public data is fair game, your collection methods, data types, and server load determine your ultimate compliance.
To protect your operations, you must respect robots.txt, throttle requests, and utilize high-quality proxy networks like NiuProxy to mirror natural human behavior.
What is Web Scraping and How Does It Work?

For digital marketers, data analysts, and SEO professionals, data is the ultimate currency. To track rankings, monitor competitors, or aggregate e-commerce pricing, teams rely heavily on automated extraction. What is web scraping? At its core, web scraping is the automated process of using software applications to extract public data from websites at scale.
Instead of a team member spending days manually copying and pasting pricing matrices or local business directories into a local document, an automated bot handles this across millions of data points in real time.
Web Scraping vs. Web Crawling: Setting the Boundaries
When discussing the legality of data scraping, engineers and lawyers often bring up web crawling. Are web crawlers legal in the same manner as scrapers? Yes, but they serve different operational purposes:
- Web Crawling: This is the process of mapping and indexing a website’s overall architectural structure, paths, and links. This is exactly how the Googlebot ecosystem discovers new content across the web.
- Web Scraping: This is the targeted extraction of specific data sets from within those mapped pages, such as pulling the exact price, reviews, or stock status of a specific retail product line.
Both methods rely heavily on automation scripts, meaning they share identical compliance frameworks, technical hurdles, and IP management requirements.
Is Web Scraping Legal or Illegal? The Definitive Answer

When building a data strategy, the first question your development or executive team will ask is direct: is web scraping legal or illegal?
The short answer is: Web scraping itself is completely legal, but how you execute it determines its legality.
The law treats automated data extraction as a dual-use technology. Much like an aerial drone, it can be used perfectly legally to inspect power lines or photograph real estate, but it becomes illegal if flown over restricted airspace or used to spy through private windows. The act of gathering data online is entirely legal when it targets public information, respects server infrastructure, and avoids personal records.
When Data Scraping is Fully Legal
- Publicly Accessible Content: Information that any standard internet user can view without setting up an account, filling out a profile, or logging in. Examples include e-commerce pricing tables, search engine results pages (SERPs), real estate listings, and business directory data.
- Search Engine Optimization (SEO) Tracking: Indexing pages to verify rankings, evaluate backlinks, and confirm site visibility parameters across diverse geolocations.
- Market Research & Aggregation: Pulling public factual info to build real-time market comparisons, academic research sets, or historical pricing models.
When Data Scraping Crosses the Line Into Illegality
Your scraping scripts cross into dangerous, actionable territory the moment you engage in any of the following technical behaviors:
- Bypassing Technical Gates: Circumventing password fields, payload encryptions, paywalls, or administrative security controls.
- Harvesting Personal Identifiable Information (PII): Extracting user databases containing real names, phone numbers, private home locations, or email records without explicit individual consent.
- Disrupting Core Infrastructure: Bombarding target servers with thousands of simultaneous concurrent connections, causing performance degradation, latency spikes, or complete system outages.
The Global Legal Landscape: Regional Compliance Breakdown
The legal boundaries surrounding web automation shift fundamentally based on geographic jurisdictions. If your enterprise is based in New York, your target servers reside in London, and your processing happens in Sydney, you must understand how regional frameworks operate.
United States: The Computer Fraud and Abuse Act (CFAA)
In the United States, historical corporate battles regarding automated scraping have centered on the Computer Fraud and Abuse Act (CFAA)—a federal anti-hacking statute designed to prevent unauthorized system intrusions. For a long time, major platforms used the threat of the CFAA to scare away data collection companies, claiming that automation constituted “unauthorized entry.”
This changed entirely with the landmark legal ruling of hiQ Labs v. LinkedIn.
- The Case: LinkedIn attempted to block hiQ Labs from scraping public profile data, issuing a cease-and-desist letter and leveraging the CFAA.
- The Final Decision: The U.S. Ninth Circuit Court of Appeals ruled that scraping data that is publicly available on the open web without a login does not violate the CFAA. The court affirmed that if a website doesn’t require an account to view its contents, it cannot invoke anti-hacking laws to stop automated data collection.
However, consider the critical caveat: is web scraping illegal under CFAA if you log into an account? Yes. If you must log into a platform (such as an internal B2B database, an enterprise dashboard, or a closed social network), you have entered a digital contract. If you scrape while authenticated, you violate the site’s Terms of Service (ToS), which can lead to severe civil breach of contract suits.
Europe & the United Kingdom: GDPR Realities
Is web scraping legal in Europe and the United Kingdom? While the EU Text and Data Mining (TDM) Directive allows automated processing for research and AI training on public data, Europe enforces the most stringent data privacy laws on earth via the General Data Protection Regulation (GDPR).
The Golden Rule of European Data Capture: In Europe and the UK, public access does not grant processing rights. Just because a professional lists their direct business email, cellular number, or personal details publicly on a forum or corporate portal does not mean you have the right to scrape it. Extracting, storing, or organizing PII within European jurisdictions without a verifiable, explicit lawful basis is a direct and heavily penalized violation of the GDPR.
Canada and Australia: Strict Enforcement
- Canada: Regulated by the Personal Information Protection and Electronic Documents Act (PIPEDA), Canadian federal watchdogs have repeatedly penalized aggregators that harvest public data sets to build automated profiles or localized commercial directories.
- Australia: The Australian Privacy Act strictly regulates personal records. The Office of the Australian Information Commissioner (OAIC) collaborates with global agencies to monitor, flag, and penalize scrapers harvesting social media indices or user profiles.
Why Is Web Scraping Risky? Technical and Civil Threats
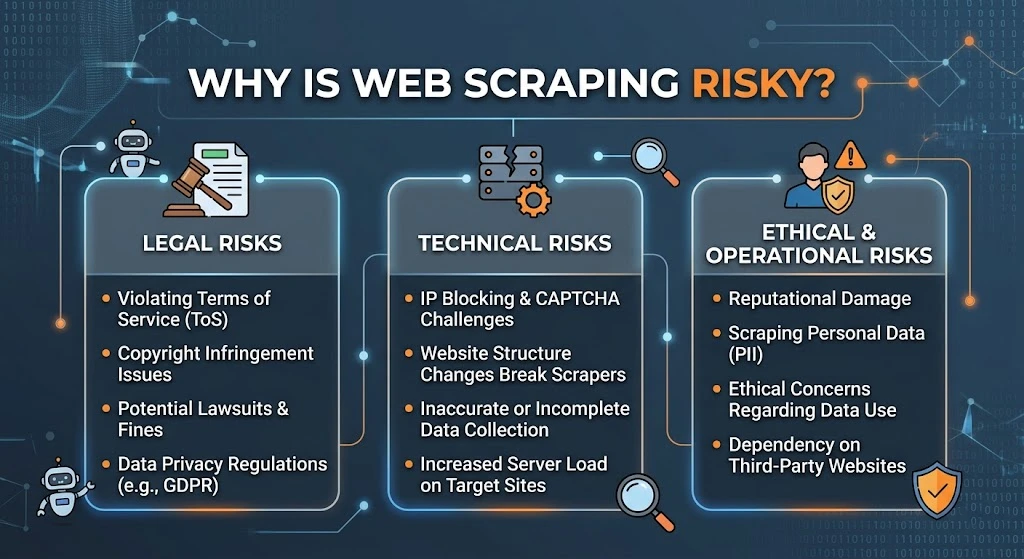
Many marketing teams scroll through forums and read misleading advice, leading them to ask: is web scraping illegal reddit users’ conversations? Or is web scraping from spotify illegal to build custom playlists?
The advice found on community forums is often legally flawed. Is web scraping risky? Absolutely. Even if your program doesn’t trigger a federal anti-hacking investigation, you can still face major corporate liability under these civil legal doctrines:
1. Breach of Civil Contract (Terms of Service)
While breaking a platform’s website rules is rarely a criminal offense, it represents a breach of contract if you agreed to those rules when creating an account. If you log in to pull data, you have accepted their digital terms. If those terms explicitly state “No Automated Crawlers or Bots,” the property owners can sue your agency for financial damages or obtain a formal court injunction to halt your business operations.
2. Trespass to Chattels
This historic common-law concept originally protected physical equipment from damage or interference, but modern courts apply it directly to web servers. If your automated scraping program fires massive volume bursts, runs thousands of simultaneous calls, spikes CPU loads, or drops site performance for human shoppers, you have committed Trespass to Chattels. The site owner has full legal grounds to sue for infrastructure damages and recovery costs.
3. Copyright and Intellectual Property Infringement
Is web scraping illegal if its factual info? No. Raw, unembellished facts—such as a flight departure time, a stock ticker percentage, a currency valuation, or a standard retail dimension—cannot be copyrighted under global intellectual property laws.
However, the creative expression surrounding those facts can be. If your scraper downloads proprietary images, original product reviews, unique blog copy, or highly stylized database layouts and copies them directly into your commercial product, you are committing copyright infringement.
Can Web Scraping Be Detected? (And How Enterprise Sites Stop You)
When launching an enterprise-level SEO audit or rank tracking campaign, your technical architecture will face defensive firewalls. Can web scraping be detected? Yes, within milliseconds. Modern websites use cloud security layers (such as Cloudflare, Akamai, and DataDome) designed specifically to isolate and neutralize non-human behavior.
Modern target sites monitor several distinct layers to catch scrapers:
- IP Reputational Metrics: Every request carries an IP address. If an IP address originating from a data center behaves like a regular human shopper, the system flags it instantly. Datacenter IPs do not browse e-commerce sites; real consumers on residential networks do.
- Rate Limitation Systems: If an individual connection requests 600 pages per minute, the firewall triggers an immediate IP ban or forces a CAPTCHA challenge. Human fingers cannot click that fast.
- Advanced Browser Fingerprinting: Security firewalls inspect incoming HTTP headers, TLS handshakes, custom user-agent parameters, and even canvas rendering configurations. If your automated script reveals that it’s running a headless engine (like Puppeteer, Playwright, or Selenium) without proper optimization, it gets blocked instantly.
- Behavioral Diagnostics: Real humans show erratic, unpredictable mouse patterns, scroll down pages with variable velocities, and pause to look at images. Automation scripts move through data matrices with predictable, mathematical precision.
How NiuProxy Solves the Data Quality and Ban Challenges
At NiuProxy, we build robust proxy networks engineered specifically to meet the high-stakes demands of digital marketers, search optimization agencies, data scientists, and scaling enterprises. We recognize that maintaining an uninterrupted data collection pipeline requires balancing technical efficiency with ethical, compliant network practices.
Our platform provides targeted network options designed to keep your scripts running smoothly, legally, and invisible to anti-bot firewalls:
| Proxy Class Infrastructure | Core Operational Utility | Best Suited For |
| Rotating Residential Proxies | Automatically cycles connections through millions of genuine, user-consented consumer home devices across the globe. | Enterprise-level web scraping, real-time e-commerce price monitoring, and localized competitor research. |
| Static ISP Proxies | Allocates dedicated, long-session residential IP addresses hosted directly within major internet service provider networks. | Multi-account management, cross-border social media marketing, and stable ad verification tasks. |
| Rotating Mobile Proxies | Routes data traffic through dynamic 3G/4G/5G mobile towers, changing endpoints automatically to mirror real mobile users. | Bypassing highly aggressive anti-scraping firewalls and validating dynamic mobile SERP results. |
| Static Mobile Proxies | Grants continuous access to fixed mobile cellular IPs for deep, uninterrupted mobile application testing. | App store optimization analysis and secure corporate account maintenance. |
| Rotating Datacenter Proxies | Delivers lightning-fast processing speeds across thousands of optimized, high-bandwidth server IPs. | Mass indexing, public domain testing, and high-velocity scraping on sites with low anti-bot security. |
Real-World Deep Dive: Real Examples of Clean Data Collection
To understand the practical intersection of infrastructure design and compliance, let’s review two anonymized operational case studies from our clients.
Case Study 1: Resolving Data Gaps in Global SEO Rank Tracking
- The Problem: A leading digital marketing agency was running daily localized keyword checks across 40 distinct regions for an international travel brand. They relied on traditional data center IP blocks. Within a week, search engine algorithms detected the repetitive, automated server requests, hitting them with endless CAPTCHAs and feeding them distorted, non-localized search results. This directly ruined their data accuracy.
- The Mitigation: The team integrated NiuProxy’s Rotating Residential Proxies coupled with targeted Static ISP Proxies mapped directly to the client’s destination cities. By spreading out the search calls, the automated rank trackers matched the network behavior of real local users in London, Tokyo, or New York. The agency restored 100% data fidelity, bypassed automated verification blocks completely, and eliminated the risk of infrastructure bans.
Case Study 2: Scraping Competitor E-Commerce Inventories Safely
- The Problem: An enterprise retail aggregator needed to harvest pricing trends across dozens of online marketplaces to feed their automated pricing engine. Their early internal scripts ran too fast from a narrow IP pool, accidentally overloading a niche merchant’s portal and triggering an IT security incident.
- The Mitigation: Our team transitioned their setup onto a distributed array of Rotating Mobile Proxies combined with strict script delays. By routing their data requests through mobile networks, their traffic blended seamlessly with cellular phone traffic. Crucially, they configured their scraper to honor the target domain’s robots.txt file and capped their scraping velocity. They secured their critical business intelligence while ensuring they never disrupted the target merchant’s server performance.
Checklist: 5 Safe Practices to Scraping Websites Legally
To keep your automated web data collection safe, fully compliant, and free from IP blocks, follow these 5 fundamental operational pillars:
1. Target Exclusively Public, Non-Copyrighted Data Sets
Ensure that every data point your script requests can be viewed on the web without logging into an account, bypassing a firewall, or accepting an intrusive user agreement. Focus your collection efforts on raw facts, public prices, business hours, and open structural metadata.
2. Formally Read and Respect the Target Site’s Robots.txt File
Before your scraper fires a single request, inspect the root directory’s [https://example.com/robots.txt](https://example.com/robots.txt) path. This file contains the explicit technical preferences of the site owners. If the document states Disallow: /inventory/, ensure your development team programs your script to avoid that directory. Honoring these files demonstrates compliance and good faith.
3. Implement Strict Rate Throttling and Request Delays
Never run your scripts at maximum hardware capacity without delays. Introduce random pause delays (e.g., between 1 and 3 seconds) between your page requests. This protects the target server from sudden, unexpected traffic spikes, preventing automated crashes and lowering the risk of civil Trespass to Chattels claims.
4. Strip Out All Personally Identifiable Information (PII)
Configure your extraction filters to completely ignore personal user details. If your scraper encounters real names, private phone lines, personal home locations, or email fields, filter them out before saving to your database. This keeps your data pipelines cleanly outside the reach of strict privacy regulations like the GDPR and CCPA.
5. Deploy an Enterprise-Grade, Diversified Proxy Architecture
Never attempt to scrape thousands of target pages from a single, static server IP. Distribute your request architecture across a diverse, high-reputation proxy ecosystem.
By leveraging NiuProxy’s premium global infrastructure, your scripts switch connections seamlessly, keeping your traffic load distributed evenly across clean, compliant nodes worldwide.
Frequently Asked Questions (FAQ)
What happens if I violate a platform’s website Terms of Service while scraping?
If you break a site’s non-authenticated Terms of Service (ToS), it is generally considered a civil breach of contract rather than a criminal act. In most cases, the platform will implement an IP ban or a technical firewall to block your automated tools. However, if your actions cause them documented financial harm or if you continue after receiving a formal cease-and-desist letter, they have grounds to pursue civil litigation against your business.
Can I legally scrape public data from major social networks?
Following the hiQ Labs v. LinkedIn precedent, public profiles that do not require an account login to view are legal to scrape under U.S. law. That said, major social networks fight automated data extraction aggressively using advanced technical firewalls and civil lawsuits. Additionally, if the profiles belong to residents of the European Union, harvesting their personal details without direct consent violates the GDPR, regardless of whether the profile is public.
Why are residential proxies safer for web scraping than datacenter proxies?
Datacenter IPs are owned by large cloud hosting companies and cloud server providers. Because normal internet consumers never browse websites using data center connections, anti-bot firewalls easily recognize these IP ranges as automated scrapers or bots and block them immediately. Residential proxies use clean IP addresses assigned by local ISPs to real households, ensuring your scraping traffic matches regular human behavior perfectly.
Is it legal to scrape data from an online store to display on my own site?
It depends entirely on what information you extract and how you present it. Pulling raw, factual product pricing or sizing specifications is completely legal. However, if you pull creative product descriptions, original brand imagery, or custom user reviews and display them on your own platform without permission, you run a high risk of violating copyright and intellectual property laws.
Key Industry Takeaways
As data engineering grows increasingly vital for modern digital strategy, staying compliant requires keeping these final truths in mind:
- Public Open Data is Legal: Collecting open, factual, non-copyrighted web data points remains protected under global legal precedents.
- Ethical Scrapers Protect Servers: Never run unthrottled, aggressive crawlers that slow down or crash a target website’s infrastructure. Maintain controlled request velocities out of professional respect.
- Privacy is Non-Negotiable: Avoid personal customer databases and PII entirely to keep your pipelines safe from severe regulatory fines.
- Use High-Quality Infrastructure: Protect your data pipelines for the long haul. Utilizing a premium global proxy engine like NiuProxy ensures your requests stay distributed, hidden, and completely compliant across clean residential, ISP, and cellular mobile connections.